Gesichtserkennung in der Kritik: Diskriminierende Algorithmen
KI-Programme erobern immer mehr Bereiche unseres Lebens. In der Regel wissen wir nicht, nach welchen Kriterien sie Entscheidungen treffen.

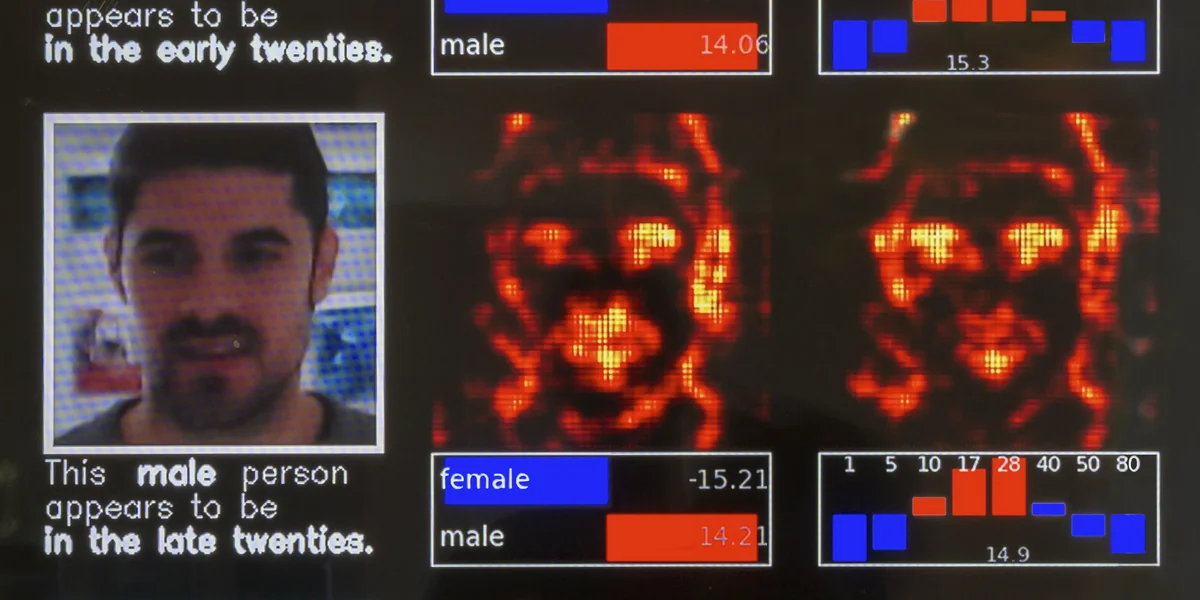
Je nach Perspektive ordnet mich das Gesichtserkennungs-Programm im Fraunhofer Heinrich-Hertz-Institut HHI in Berlin als Frau oder als Mann ein, manchmal ist es sich unsicher. In den meisten Fällen liegt es aber richtig. Richtig, wenn man eine Binarität der Geschlechter voraussetzt und innerhalb dieser Binarität anerkennt, dass ich mich als Frau inszeniere.
Mein Alter wird zwischen „young teenager“ und „young adult“ geschätzt. Das entspricht nicht meinen 28 Lebensjahren, aber da mein Alter gewöhnlich zu jung geschätzt wird, ist auch diese Ausgabe des Systems realistisch.
Das Programm ist eine Demoversion und wurde von Sebastian Lapuschkin mitentwickelt, der am Fraunhofer HHI forscht. Auf der letztjährigen CeBIT Hannover wurde sein Alter von eben diesem Programm hartnäckig zu hoch geschätzt. Warum? Er trug an diesem Tag ein Hemd und der Algorithmus hatte zuvor auf einem öffentlich verfügbaren Datensatz gelernt, dass Menschen, die Hemden tragen, tendenziell älter sind. Diesen Zusammenhang hat ihm niemand beigebracht, das Programm hat ihn von selbst hergestellt.
Transparent zu machen, auf welchen Kriterien solche Fehlschlüsse der „künstlichen neuronalen Netze“ beruhen, ist eines der Forschungsziele von Wojciech Samek, der die Forschungsgruppe zum maschinellen Lernen im Fraunhofer HHI in Berlin leitet. Er und sein Team haben zusammen mit Kolleg*innen von der TU Berlin eine Technik entwickelt, die den „Entscheidungsprozess“ eines Algorithmus zurückverfolgt und somit aufzeigt, anhand welcher Kriterien ein bestimmter Output zustande kommt.
Ungeahnte Möglichkeiten
Für die WissenschaftlerInnen am Fraunhofer HHI Berlin steht fest, dass KI in Zukunft immer mehr Anwendung finden wird. Wir kennen sie im Privatleben bereits als „Siri“, die unsere natürliche Sprache erkennt oder von individualisierter Werbung, die auf unser Online-Verhalten zugeschnitten ist.
Auch im medizinischen Bereich scheint die Bandbreite an Möglichkeiten zur Einsetzung von KI noch ungeahnt. So können Algorithmen bereits Bilder von Zellen analysieren und wichtige Hinweise auf Erkrankungen geben.
Wojciech Samek vom Fraunhofer HHI weist daraufhin, dass das ein großes Potential birgt: Die Programme könnten relevante, bisher unbekannte Korrelationen aufzeigen, denen tatsächlich eine kausale Beziehung zugrunde liegt. Auf diese Weise wäre KI in der Lage, Wissen zu generieren.
Algorithmus mit Vorurteilen
Erst Ende Oktober bestätigte Amazon, dass es mit der US-Einwanderungs- und Zollbehörde (ICE) in Verhandlungen bezüglich einer Kooperation im Bereich der Live-Gesichtserkennung steht. Die von Amazon entwickelte Technologie „Rekognition“ kann in nur einer Sekunde ein Gesicht aus einer Menschenmenge (zum Beispiel in einer Überwachungskamera) mit einer Datenbank von 10 Millionen Gesichtern abgleichen.
Doch die Technologie steht wegen Fehleranfälligkeit in der Kritik. Eine kürzlich durchgeführte Studie der NGO American Civil Liberties Union (ACLU) bestätigte das: Bilder von den 535 Mitgliedern des Amerikanischen Kongresses (SenatorInnen und Abgeordnete) wurden mit 25.000 veröffentlichten Täterfotos abgeglichen.
Dabei zeigte „Rekognition“ insgesamt 28 falsche Übereinstimmungen. Bei 40% dieser 28 falschen Identifizierungen wurden People of Colour (PoC) fälschlicherweise als TäterInnen identifiziert. Der Gesamtanteil von PoC im Kongress beträgt allerdings nur etwa 20%. Der enorm leistungsstarke Algorithmus scheint vorurteilsbehaftet zu sein.
Das Ausgangsmaterial ist entscheidend
Um einen Algorithmus zu trainieren, muss er zunächst mit möglichst vielen Daten konfrontiert werden. Für die Gesichtserkennung wird das System daher mit einer großen Menge an Bildern von Gesichtern gefüttert, die zuvor gelabelt wurden. Ein mögliches Label ist die Kategorie „Geschlecht“. Der Algorithmus lernt schließlich, Verknüpfungen zwischen diesen Labeln und bestimmten visuellen Merkmalen – im Grunde Pixelanordnungen – auf den Bildern zu ziehen.
Ein Beispiel: Das Vorkommen eines Bartes in einem Gesicht korreliert wahrscheinlich sehr häufig mit dem Label „Mann“. Erkennt das Programm dann ein Bild mit dem visuellen Eindruck eines Bartes, spuckt es wiederum das Label „Mann“ aus.
Die möglichen Probleme sind offensichtlich: Fehlerhafte oder klischeehafte Label führen zu fehlerhaften oder klischeehaften Outputs. „Die Datensätze müssten eigentlich von Experten gelabelt werden“ meint Wojciech Samek vom Fraunhofer HHI. Tatsächlich werde diese mühevolle Arbeit oft ausgelagert und das mindere die Qualität der Datensätze.
Repräsentation und Bildqualität
Ein weiteres Problem ist laut Samek die Repräsentation von Personen in den Datensätzen. Wäre beispielsweise eine ethnische Gruppe in den Datensätzen unterrepräsentiert, werde der Algorithmus bei Konfrontation mit einer solchen Person ungenauer. So fiel es einem Programm besonders schwer, das Alter von asiatisch aussehenden Menschen zu bestimmen, einfach weil der Trainings-Datensatz weniger Bilder von asiatisch aussehenden Menschen enthielt.
Auch die Bildqualität des Ausgangsmaterials ist relevant. Die Standardeinstellungen vieler Kameras sind für die Belichtung hellhäutigerer Personen kalibriert. Das führt dazu, dass die Bilder von Personen mit dunklerer Hautfarbe häufiger schlecht belichtet sind. Diese schlechtere Qualität des Bildes macht wiederum die Identifizierung häufiger fehlerhaft. „Es ist enorm wichtig, sichere Standards zu entwickeln, die bestimmte Normen und Qualitätskriterien einhalten.“ betont Samek.
Dieses Problem betrifft nicht nur den juristischen Bereich. Auch im Gesundheitssektor kann es entscheidend sein, dass der Algorithmus, der bestimmte Hautmerkmale auwerten soll, mit Bildern von diversen Hautfarben trainiert wurde.
Einheitliche Qualitätsstandards
Auf einer Konferenz im November zum Thema „Künstliche Intelligenz in der Medizin“ soll genau darüber diskutiert werden. In Zusammenarbeit mit der WHO (World Health Organization) organisiert die ITU (International Telecommunication Union) dieses Zusammenkommen, um weltweite Standards zur Anwendung von KI in der Medizin zu entwickeln.
Wojciech Samek wird auch daran teilnehmen, denn seine Forschung fokussiert sich darauf, Licht in die „Blackbox“ zu bringen: Er und sein Team verfolgen den „Entscheidungsprozess“ von Programmen zurück und machen so transparent, nach welchen Kriterien ein Algorithmus zu einem Ergebnis gekommen ist. Dadurch entlarven sie zufällige Korrelationen und verbessern die Performanz der Programme.
Vor der Verwendung der Gesichtserkennungstechnologie von staatlichen Behörden, wie im Fall von Amazon warnt Samek: „Es ist natürlich hochproblematisch, wenn solche Systeme zum Beispiel in der Täteridentifizierung angewendet werden, ohne dass nachvollziehbar ist, nach welchen Kriterien sie jemanden erkennen“. Momentan wäre die Nutzung dieser Technologie höchstens als Ergänzung sinnvoll. „Die Algorithmen lernen Vorurteile mit, wenn diese in den Datensätzen schon drin stecken.“
Würde ein Programm mit Datensätzen trainiert, die prozentual mehr Menschen mit dunklerer Hautfarbe als Täter ausweisen, dann lernt der Algorithmus das. Bei einer Polizeikontrolle mit Live-Gesichtserkennung ist jede Person mit dunklerer Hautfarbe also verdächtiger für diesen Algorithmus.
Bedenken kommen auch von Amazon-MitarbeiterInnen. In einem anonymen, offenen Brief fordern sie das Ende der Verhandlungen mit der US-Behörde ICE. Die Nutzung von „Rekognition“ durch den US-Staat wäre ein Schritt in Richtung Massenüberwachung und mögliche Konsequenzen seien nicht absehbar.
Neben der Fehleranfälligkeit der Algorithmen hätte die Nutzung von „Rekognition“ durch die US-Regierung weitere problematische Implikationen: Wenn Kameras in der Nähe von Schulen, Krankenhäusern und Gebetshäusern hängen, würden Menschen ohne legalen Aufenthaltstatus davon abgehalten, diese teilweise lebensnotwendigen Einrichtungen aufzusuchen.
Dieser Umstand verdeutlicht die Relevanz des interdisziplinären Teams im Fraunhofer HHI. Was Samek und seine MitarbeiterInnen fordern, entspricht so einer Grundlage moderner Moralphilosophien: Wer eine verantwortungsvolle und in diesem Sinne moralische Entscheidung treffen will, muss wissen, wie sie gerechtfertigt ist. Und Rechtfertigung bedeutet, gute Gründe für eine Entscheidung zu haben. Wenn KI in Zukunft an relevanten Stellen einer Gesellschaft eingesetzt wird, dann muss der Entscheidungsprozess der Programme also transparent und streng kontrolliert sein.
50.000 Menschen beteiligen sich bei taz zahl ich – weil unabhängiger, kritischer Journalismus in diesen Zeiten gebraucht wird. Weil es die taz braucht. Dafür möchten wir uns herzlich bedanken! Ihre Solidarität sorgt dafür, dass taz.de für alle frei zugänglich bleibt. Denn wir verstehen Journalismus nicht nur als Ware, sondern als öffentliches Gut. Zahlen muss niemand, aber guter Journalismus hat seinen Preis. Und immer mehr Leser*innen machen mit und entscheiden sich für eine freiwillige Unterstützung der taz! Dieser Schub trägt uns gemeinsam in die Zukunft. Denn wir suchen wir auch weiterhin Ihre Unterstützung. Setzen auch Sie jetzt ein Zeichen für kritischen Journalismus und unterstützen Sie die taz – schon ab 5 Euro. Jetzt unterstützen





meistkommentiert